Code
# Read data
import pandas as pd
from plotnine import *
data=pd.read_csv('data/data.csv')
# First letter of full name
first_letters=data['name'].str[0].value_counts()
# first_letters # Read data
import pandas as pd
from plotnine import *
data=pd.read_csv('data/data.csv')
# First letter of full name
first_letters=data['name'].str[0].value_counts()
# first_letters # Plot for first letter of full name
first_letters=pd.DataFrame(first_letters.head(15))
first_letters.index=pd.Categorical(first_letters.index,categories=first_letters.index,ordered=True)
(ggplot(first_letters,aes(x=first_letters.index, y=first_letters['count']))
+ geom_bar(stat='identity', fill='steelblue')
+ theme_classic()
+ labs(title='First letter of full name',x='First letter',y='Count')
)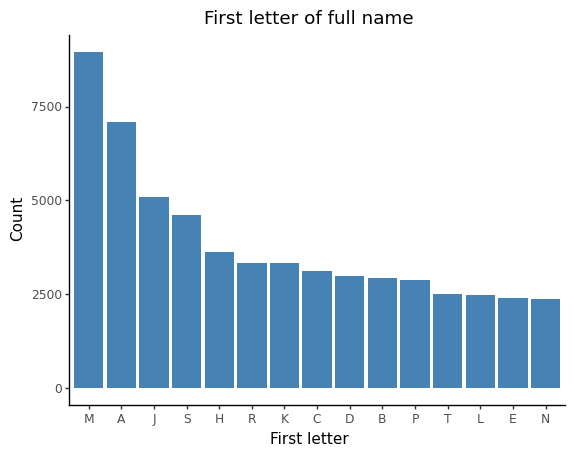
When analysing the bar chart for groupings to do with the first letter of the name there is no distinct or noticeable trend among the alphabets that most politicians’ names start with.
This is substantiated by A; the first letter of the alphabet having the second highest percentage of political representatives, while the highest percentage of political representatives’ names starting with M which is halfway down the alphabet.
The high number of Ms could be due to the prevalence of the name Mohammed, the most common name in the world. In total, 1666 MPs have the name Mohammed or one of its variants. The same is true for J, otherwise an uncommon letter, which is due to the prevalence of the name John or its variants. 1576 MPs have the name John or one of its variants.
# First letter of family name
last_name_letters=data['family_name'].dropna().apply(lambda x: x[0]).value_counts()
# last_name_letters
# Plot for first letter of family name
last_name_letters=pd.DataFrame(last_name_letters.head(15))
last_name_letters.index=pd.Categorical(last_name_letters.index,categories=last_name_letters.index,ordered=True)
(ggplot(last_name_letters,aes(x=last_name_letters.index, y= last_name_letters['count']))
+ geom_bar(stat='identity', fill='green')
+ theme_classic()
+ labs(title='First letter of family name',x='First letter',y='Count')
)
# y=first_letters['count']))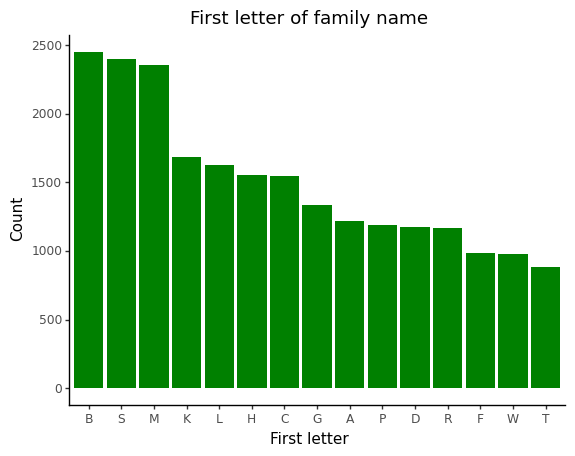
The letters B, S, and M are the most common for surnames. However, in the absence of reliable global-level population data for names, we are unable to compare this frequency and ascertain the relative prevalence of names.